


The Mining of training data

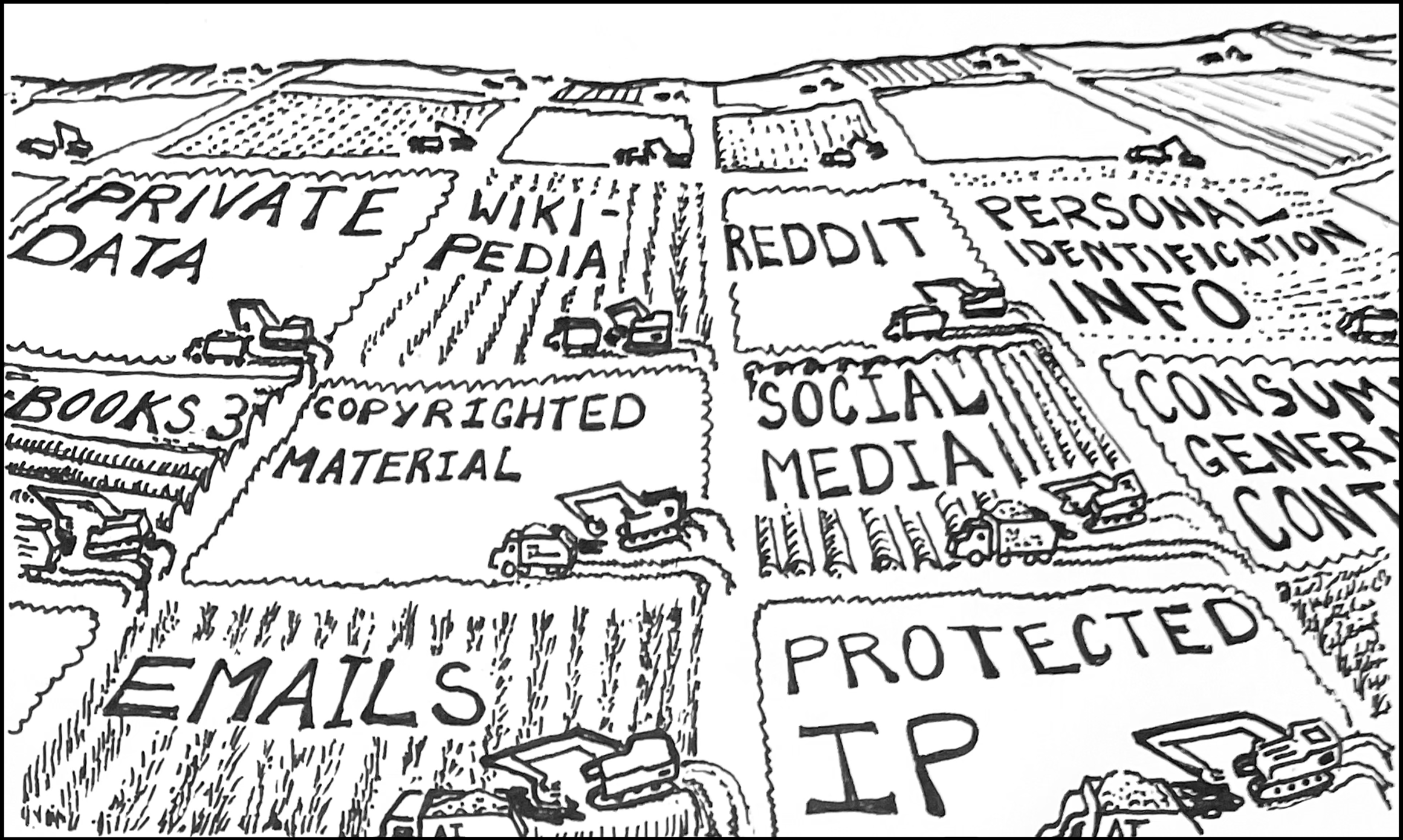
Training data is the information gathered across the internet used to create answers and images. Training data can take the form of Reddit, Wikipedia, personal social media pages, both free and paid media outlets — AI uses everything, to the tune of billions of pages each month for a given generative AI model.
How Large language models work


-
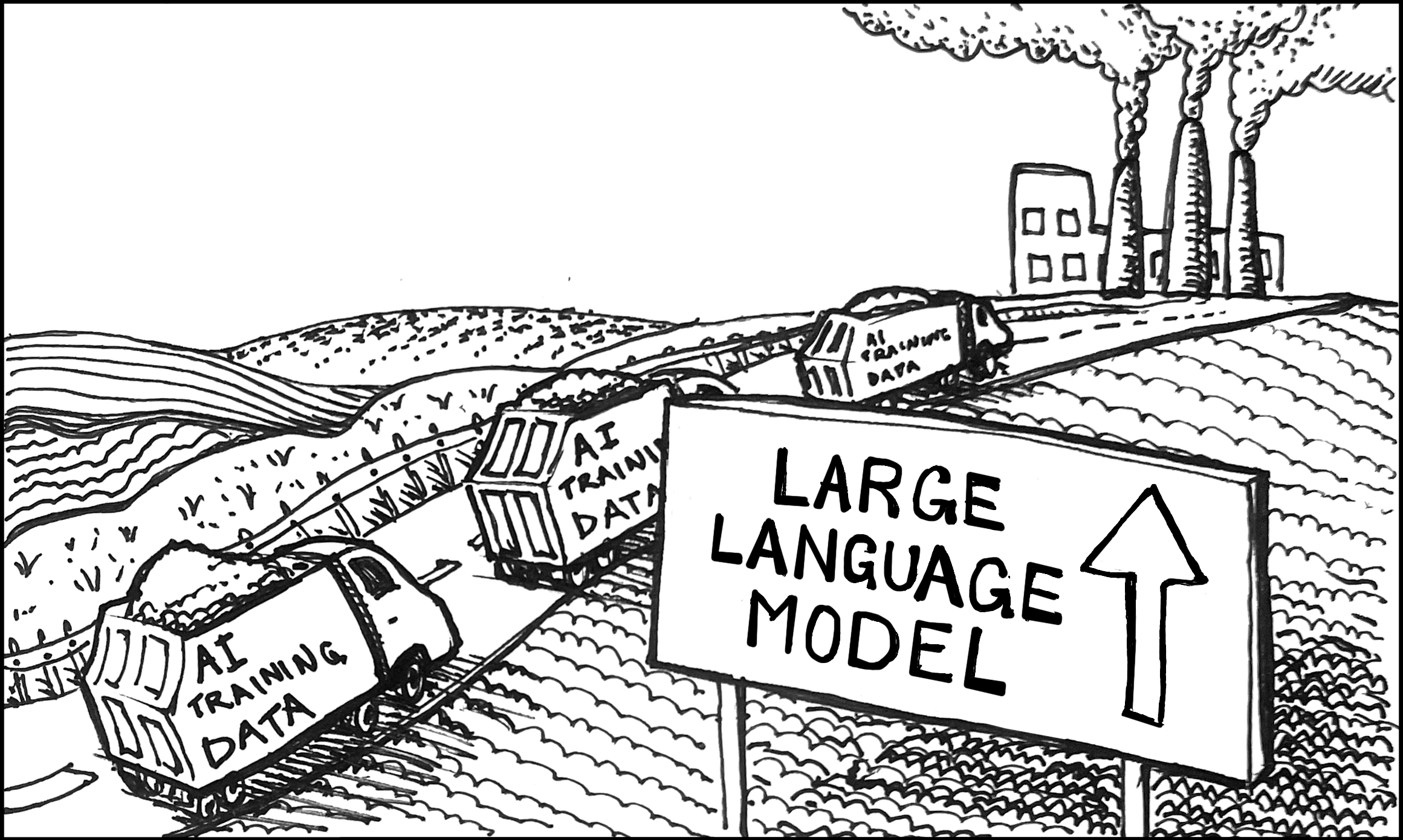
Model developers “acquire” content that is used as the primary input to train the model — acquisition happens through web scraping, shadow databases (including copyrighted content) and content uploaded by end users to various cloud-based platforms.
Copyrighted content
Web pages/content
Social media
Personal ID information
Confidential data
Photos and video content

-
Content is reviewed using automated and manual processes to understand if it can be used to train a model. Issues arise because, at the massive scale of billions of pages involved for impossibly broad generative AI projects, developers make:
No effort to verify rights or if content can be used for model training
No effort to understand if content is objectionable, illegal, unsafe, factual
No effort to check if content was generated using AI

-
Model training is the process whereby the model code (software) ingests and processes the training data to improve its ability to generate output that appears intelligent to a human user.
Model training is “self supervised” - limited human oversight or supervision
Model developers provide no transparency in model structure resulting from training

-
Deployed AI - this allows the LLM or more specialized (image/video) models to be accessed by end users.
User prompts model for response e.g. ask ChatGPT to answer a question or create an essay, ask Dall-E to generate an image based on the prompt

-
Models produce output which is probabilistic and may contain:
Hallucinations - factual inaccuracies in the model output that may be caused by the training data
Misinformation - hallucinations that replicate false claims that may be caused by the training data
Malice - objectionable, illegal and otherwise harmful content generated by a model

-
AI generated content is published across the web. From there, it’s ingested and processed by LLMs as training data. There are no LLMs that reliably determine if new training content is human or AI generated.
This process further pollutes training data, creates a circular pattern, and leads to increased potential for perpetuating misinformation and other harmful content
Dangers of no regulation
the outsized Impacts of Training Data

Training data is the foundation for which Artificial Generative Intelligence is built. As such, it has outsized impact on some of the biggest forward-looking impacts that these systems will have on public trust, safety, and consumer protection. This is why training data transparency and accountability must be addressed immediately in public policy.
Without any transparency in information sourcing, the general public will become increasingly reliant on a system that has no accountability. In addition to the risk of rampant misinformation, the mere awareness of its fallibility further erodes public trust in true information.

Threatens data privacy.
Without action, PII (personally identifiable information) via social media content or otherwise is being used without knowledge or consent. This means unregulated access to personal information and user content.

Threats to our children.
As is often the case, children are not immune to being victimized by AI. In addition to having sensitive information scraped from social media and other web inputs, there are numerous cases of pornographic images of underaged children created by AI.

Strengthens Big Tech monopolies.
Recent history, and accompanying anti-trust lawsuits, have revealed predatory, monopolistic behavior by the world’s largest Big Tech companies. Allowing unfettered access to unregulated training data, especially since they have a multi-year head start where no one was told how much training data was being ingested into their LLMs, will further compound their concentration of power because with their endless computing power and talent resources, they will be able to ingrain their AI products too deeply into society, too quickly.
It strips power & control from content creators.
Content creators and businesses are not being compensated, or recognized, for providing the input information training generative AI outputs. Although a small handful of publishers big enough to track and protect their data have licensing deals in place, most recent lawsuits filed by the New York Times and SAG members claim billions of dollars in damages from copyright infringement used solely for AGI outputs.

Spurs whack-a-mole policy.
Regulatory efforts that focus on outputs will lead to a scattershot approach that ignores the root problem: The lack of transparency over where information comes from in terms of traceability back to the input - training data. Holistic regulation including transparency and auditability of training data as an input Broader regulation is the only way to unify regulation.