
Illustration by FolsomNatural
AI Transparency For the Greater Good

The Transparency Coalition is working to create AI safeguards for the greater good. We believe policies must be created to protect personal privacy, nurture innovation, and foster prosperity.
Artificial intelligence has the potential to be a powerful tool for human progress if properly trained, harnessed, and deployed.
It begins with transparency.
Fair-minded business and government leaders have created systems to ensure the safety and transparency of the financial industry, the construction industry, the food and drug industries, and the commercial aviation sector. We can and must do the same with artificial intelligence.


Photo by Adi Goldstein
Here’s where Policymakers should start.
-
Existing privacy and copyright laws should be applied to the development and deployment of AI systems.
At the federal level
The Federal Trade Commission is currently limited to the enforcement of data privacy harms within the construct of deceptive or anti competitive business practices. For example, the FTC recently carried out an action against the online therapy provider BetterHelp for promising one thing (keeping personal data private) and doing the opposite (selling it to Facebook and Instagram). In January, the FTC launched an inquiry into five big tech companies and their partnerships with generative AI developers, but only based on antitrust concerns.
FTC officials should continue to scrutinize the AI industry—but Congress must give it the legal authority to truly protect data privacy, not just nibble around the edges.
At the state level
Data privacy law is currently a state-by-state patchwork due to the absence of an overarching federal data privacy act. Eighteen states have passed data privacy acts, and more are expected to follow.
Enforcement of these laws depends largely on each state attorney general, although some states allow individuals to file private lawsuits against companies for noncompliance.
We believe many of these laws apply to the unauthorized use of personal information in AI training datasets. State attorneys general should prioritize the investigation of noncompliance with data privacy laws in the development of AI models.
Examples of recent state data privacy law enforcement actions include:
• California: the California Consumer Privacy Act (CCPA) and the California Online Privacy Protection Act (CalOPPA) exist to stop the illegal use of personal data. The California Attorney General recently carried out enforcement actions against DoorDash and Sephora for selling personal information without informing consumers or honoring opt-out requests.
• Connecticut: In the six months since the Connecticut Data Privacy Act took effect, the state AG has initiated inquiries into data brokers, a teen-oriented app, an auto manufacturer, and a grocery store for noncompliant use of personal data and biometric information.
• Illinois: The 15-year-old Biometric Information Privacy Act (BIPA) allows for private rights of action. That has resulted in enforcement via class-action lawsuit against companies like Facebook and White Castle, who had wrongly collected and used biometric data.
• Virginia: Virginia Consumer Data Protection Act grants the state attorney general exclusive enforcement powers. Private rights of action are not allowed. Since the law went into effect in Jan. 2023, Virginia AG Jason Miyares has said very little about enforcement of the Act, leading some to wonder if the Act is being enforced as intended.
-
Training data is the foundation of every AI system. Developers of systems like ChatGPT have trained their models using massive datasets without licensing or obtaining permission to use that data. That must end.
AI model developers and owners must be required to obtain the legal right to use training datasets. This is common across many industries. Musicians license their songs for use in movies and advertisements. Athletes sign name-and-likeness licensing deals with shoe companies. Developers license the software they create. AI companies building billion-dollar brands should not be exempt from this routine business practice.
Specifically, AI model owners must meet one of the following three criteria on all training data:
1) They own their training data.
2) They have a license to use their training data and can verify that the licensed training data was collected legally.
3) They have an opt-in right to use personal data, including the “right to be forgotten” to meet privacy laws, or an opt-in right to other digitized information on the internet.
AI model owners must have legal license to use training data they employ, and that license must be auditable and traceable.
-
Developers and deployers of AI systems should be required to provide documentation for all training data used in the development of an AI model.
This type of auditable information set provides transparency and assurance to deployers, consumers, and regulators. It’s similar to the SOC 2 reports that are standard in the cybersecurity industry. SOC 2 reports, issued by third-party auditors, assess and address the risks associated with software or technology services.
A Data Declaration is not necessarily tied to government oversight. Rather, we believe it should become a standard component of every AI model—expected and demanded by AI system deployers as a transparent mark of quality and legal assurance.
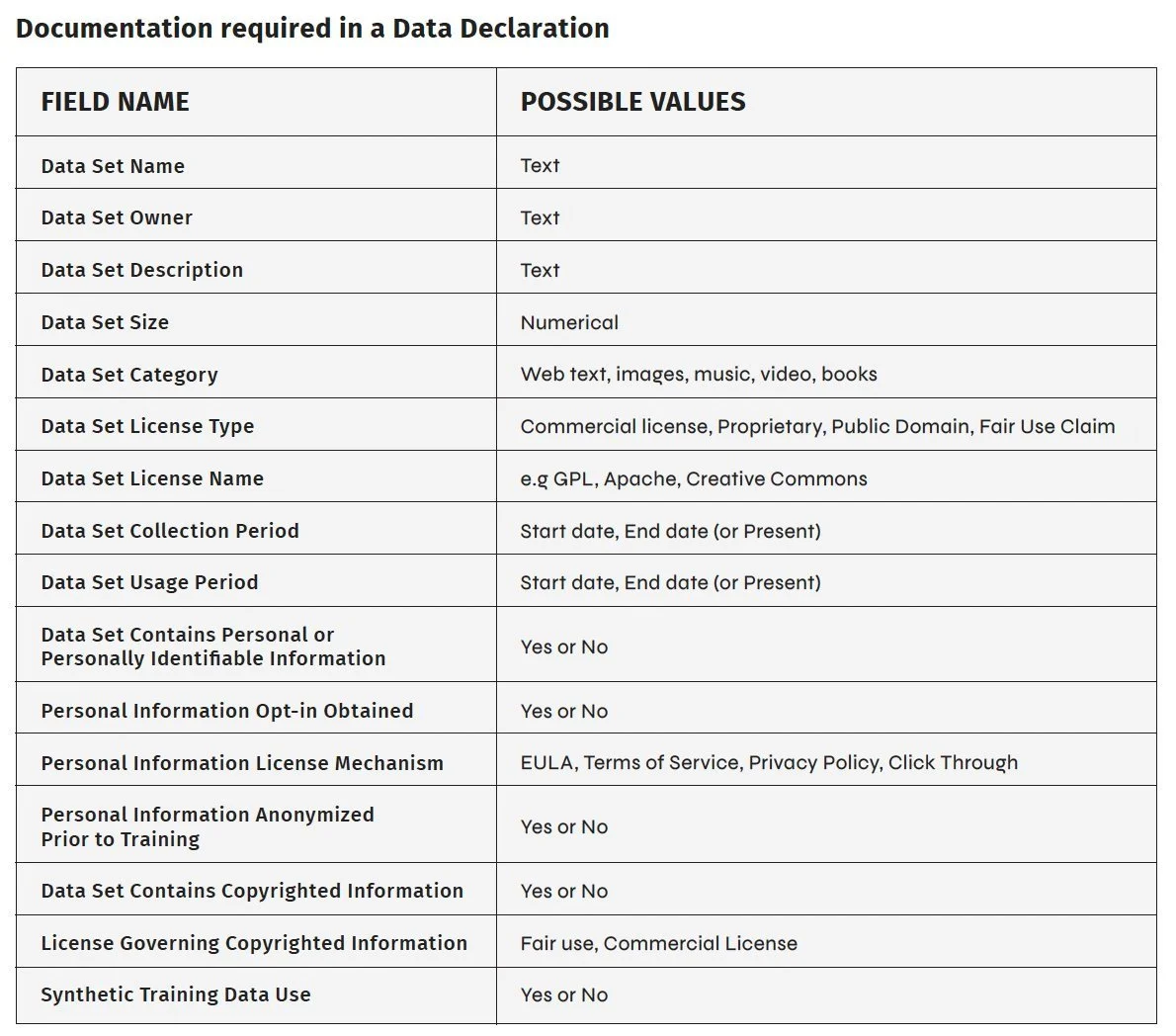
The Transparency Coalition has formulated a Data Declaration that would contain basic information about the data used to train the AI model. For more details see the TCAI Data Declaration chart at the bottom of this Solutions page.
A number of other data card formulations have been proposed, including Datasets for Datasheets, Data Cards, and Dataset Nutrition Labels.
-
Consumers and small businesses sign up for many online services. They are presented with many pages of terms of service (ToS) with pages of opaque legal statements.
A small sentence buried within 12 pages of legal jumble saying “your data may be used to improve our products” should not cover AI uses. There is a big difference between tracking product bugs and use cases under that umbrella statement versus using everything a user does and everything they input or create to train an LLM like ChatGPT.
Some state data privacy laws now require opt-out options for consumers. That’s a good first step, but when it comes to the use of personal data for AI model training the standard should be the strong opt-in model.
Under the opt-in model, consumers would deliberately affirm their desire to allow a company to use their data for future AI model training. Consumers declining to opt-in must be given a legitimate remedy beyond a simple denial of service. If their data, search input, or content created while using the product is going to be used for AI model training, that usage needs to be deliberately affirmed with an opt-in choice.
-
Audit mechanisms are common tools used to manage risk and earn consumer trust. They are an everyday feature of the financial, medical, food processing, and software industries. As artificial intelligence becomes a more integral part of our daily lives, appropriate audit mechanisms must be integrated into the development and deployment of AI systems.
Those mechanisms must align with state and federal data privacy protection laws. Working together, AI developers and deployers can build an audit-ready culture that maintains legal compliance while encouraging innovation and building consumer trust.
On the enforcement side, fines levied against noncompliant companies must be based on a percentage of revenue. This is the only appropriate basis for meaningful enforcement. Without a fine structure based on revenue percentage, the payment of relatively miniscule fines will become a built-in cost for big tech companies—the cost of doing business.
TCAI policy solutions
this is a data declaration.
It’s simple and easy. Every AI model should have one.
Developers of AI systems should be required to provide documentation for all training data used in the development of an AI model.
This type of auditable information set provides transparency and assurance to deployers, consumers, and regulators. It’s similar to the SOC 2 reports that are standard in the cybersecurity industry. SOC 2 reports, issued by third-party auditors, assess and address the risks associated with software or technology services.
A Data Declaration is not necessarily tied to government oversight. Rather, we believe it should become a standard component of every AI model—expected and demanded by AI system deployers as a transparent mark of quality and legal assurance.
The Transparency Coalition has formulated a Data Declaration, shown at right, that would contain basic information about the data used to train the AI model.
A number of other data card formulations have been proposed, including Datasets for Datasheets, Data Cards, and Dataset Nutrition Labels.
TRANSPARENCY COALITION AI BILL TRACKER
Stay up to date on AI-related bills introduced in the 2024 state legislative session in all 50 states with our interactive map.
Contact Us
If you’re a policymaker or lawmaker and wish to contact us, please fill out this form.